Blog table內有tags這個varchar欄位
value為"tag1, tag2, tag3"這樣
當以tag搜尋文章時,就用sql以%tag%方式去找
但問題是
當blog 1的tags是test
blog 2的tags是iq-test
如果我用%test%去找,會連帶blog2都找出來,這樣並不是tag機制理想的運作方式
解決方式有二
- 設計一個many-to-many的連接表blog_tags和tags,
CREATE TABLE [dbo].[blog_tags](
[blog_id] [int] NOT NULL,
[tag_id] [int] NOT NULL
) ON [PRIMARY]
CREATE TABLE [dbo].[tags](
[id] [int] IDENTITY(1,1) NOT NULL,
[tag] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_tags] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
最後每一個新增的文章都會自動加進這兩個表,當要以tag找文章時,就用tag去找tags.id,再從blog_tags找blog_id。
但這樣會多出2個表,將來較難維護,而且新增文章都要用stored procedure,同時insert tags和blog_tags,限制很多。
好處是標準化,理論上blog不用再儲存tag,改用blog_tags儲存,每一行blog不再儲存重覆的tag數據
-
使用sql server 2016新引入的string_split
select * from blog b
where exists(select * from string_split(b.tags,',') where trim(value)='test')
好處是維持只有blog一個表,簡潔方便,而且效能也更快,以下為execution plan:
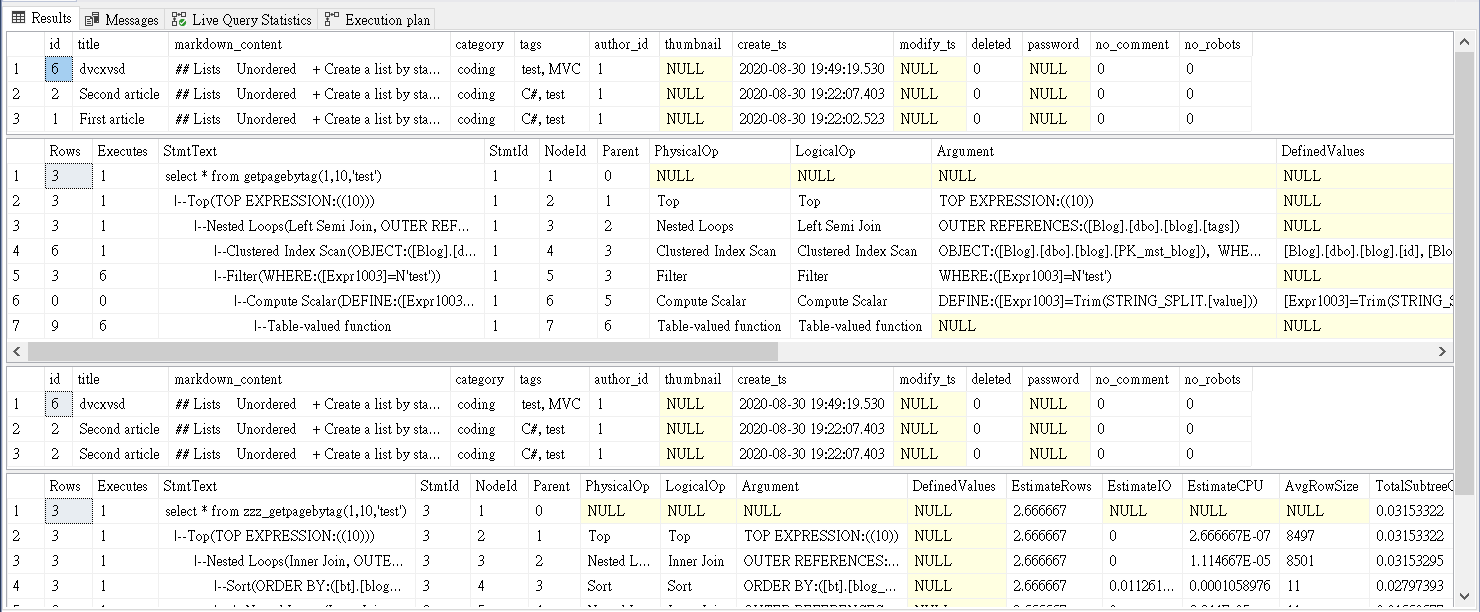
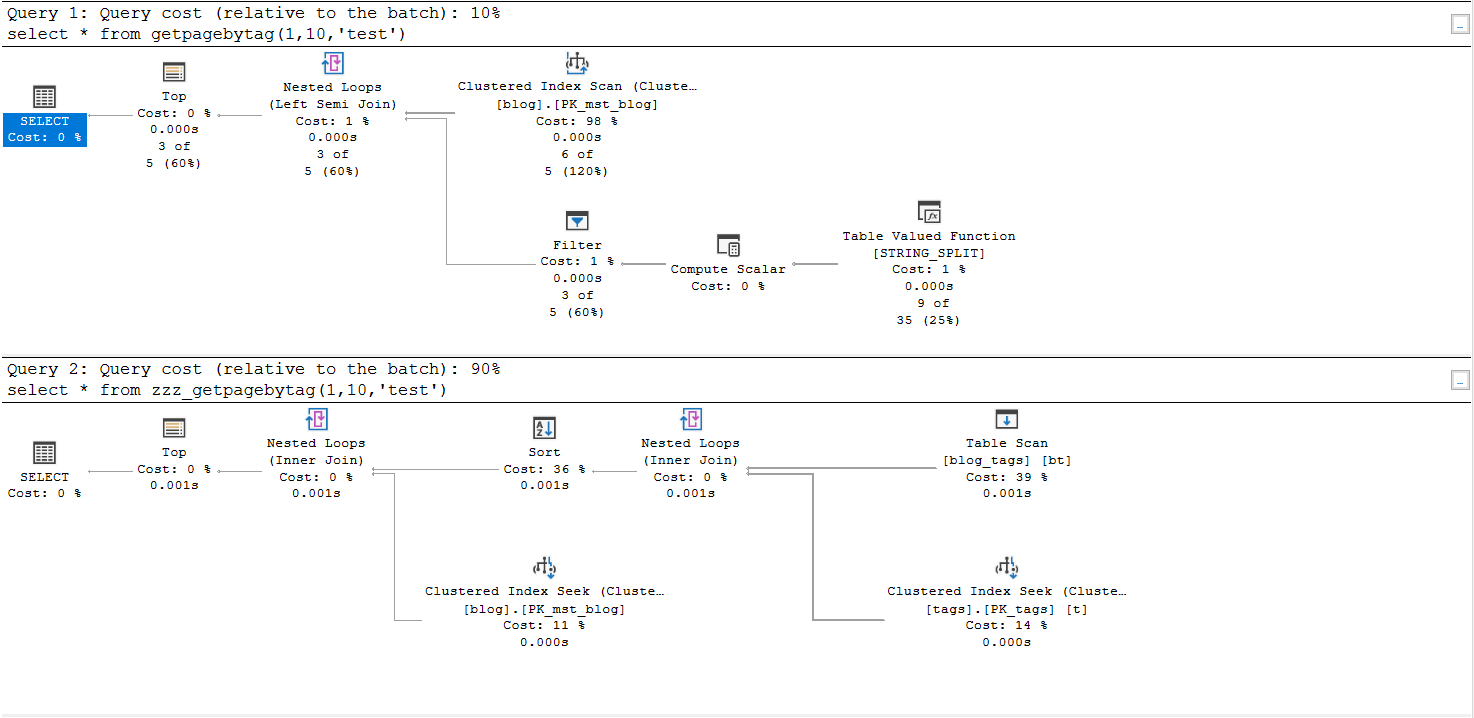
壞處是重覆儲存tag,不夠標準化(假設你有1000篇文章tag了C#,你的TABLE就有1000個C#。如果用id的話,你只儲存了1000個數字id,再用id去找它是什麼tag)
、以及將來換DB可能會後悔。
而且,當我只想找各個tag有多少文章時,要歷遍一次blog的tags欄位,而方法一因為早就儲存了,由於我的首頁進去就看到tags list,這個部份可能要講究效能,但假設一個文章有3個tag,那blog_tags就有3行,再join tags抓名稱(3個string),和直接歷遍blog的tags欄位(3個string加2個逗號,沒joining)其實也沒多大差別。
這裡只是小project,所以我選了較方便的方法二。
其實這個問題我到現在也很糾結,所以實際上我也開了方法一的TABLE,而且每次新增文章時都有insert進去,但sidebar的tags堆則是用string_split的方法處理。
Blog專案 - 內文 (Controller, view)
惡耗! 網站剛上線就發現本來在用的SSL供應商取消了免費政策!
MikeChan